The first thing I did when playing around with historical wrestling data back in 2020 was figure out what the average outcome was by seed. A #1 seed doesn’t always finish on top of the podium. As a matter of fact, they finish #1 roughly half the time. A #1 seed doesn’t even finish top 8 all the time. Though that is pretty close. The #1 seed AA’s roughly 98% of the time.
The following year I layered in placement points and an estimate of advancement points scored based on the “average” path to a placement. A few years later I came up with a real rough estimate of bonus points scored by seed. From these humble beginnings I could estimate what the average points a particular seed would score. Let’s call that the expected points.
Over time I have refined the inputs to make the outputs a little more accurate. And now that Wrestling.Guru has created the ultimate/most accurate/most complete NCAA wrestling tournament historical database1, the expected points model will be even better next season.
All Models Are Wrong But Some Are Useful
The first few years I had expected points I used the raw numbers. But this has some problems. Given the number of rule changes that have occurred for everything from seeding, to scoring, to qualification, to numbers of AA’s, to wrestleback criteria and bracket size, it is problematic to have too long of a lookback period. If your lookback period is too long you are comparing apples to oranges.
However, sometimes, over short periods of time, a particular seed may do particularly well, or especially poorly. If your lookback period is too short you model gets drawn toward outliers.
To “solve” the problem I only use data from the 16 and 33 seed eras (2014-present)2 for expected points AND I fit the data in two directions with multiple iterations to create a model that satisfies the constraints that the sum of all placement probabilities for a single wrestler is 1 and the sum of all wrestlers’ individual probabilities at an each placement position also equals 13.
That looks a little something like this:
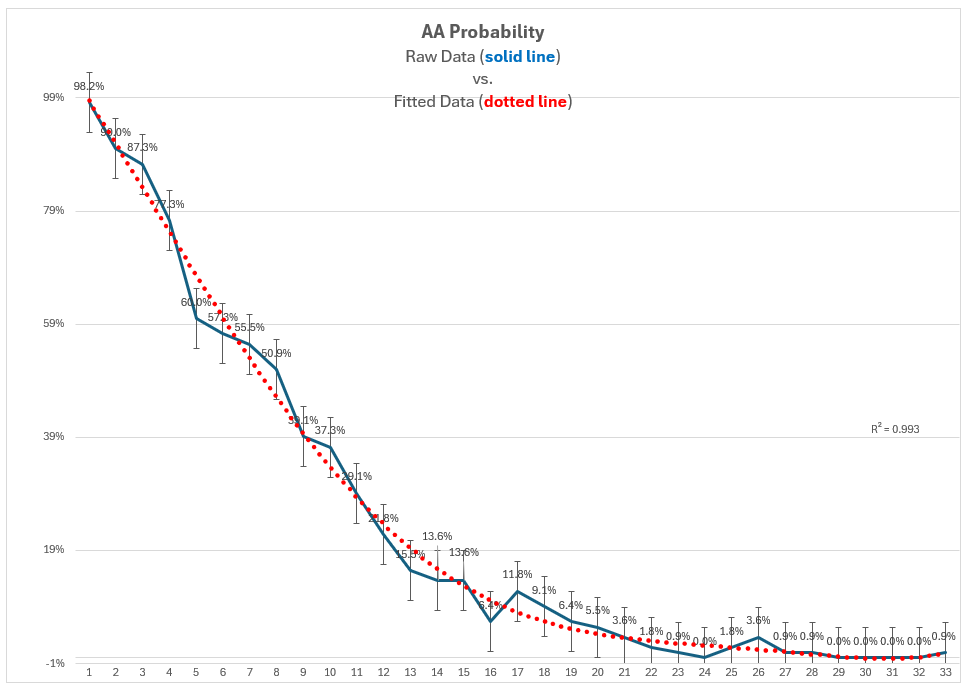
To understand why solve is in quotation marks, just look at the heading of the section.
Enough Words. Where Are The Numbers?
Bonus. You get another picture with the numbers.
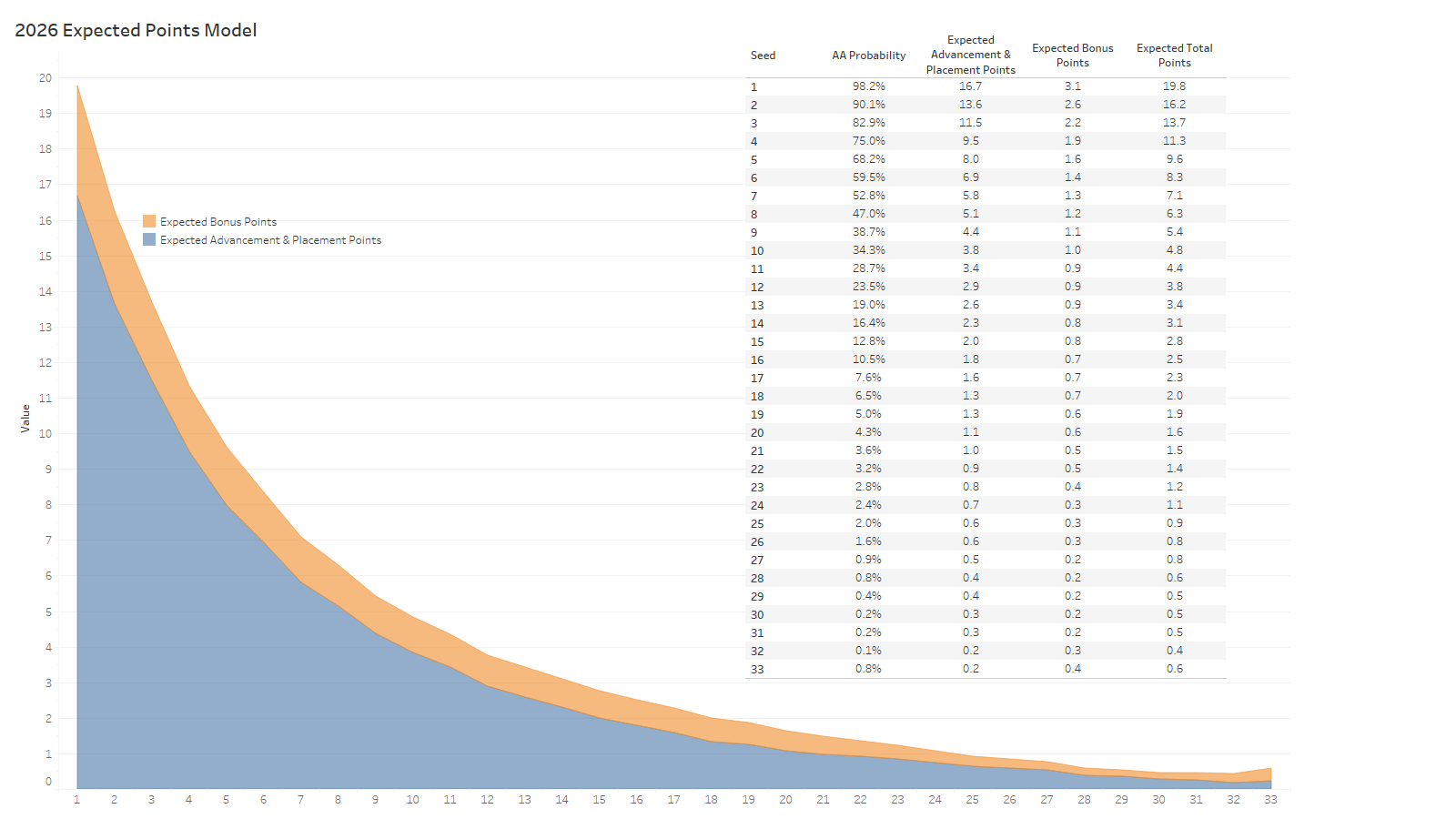
If everything goes to plan, a #1 seed can score between 20 and 30 points by finishing first. But as you can see from the table and graph, including bonus they are expected to score 19.8 points. Another way of saying that is the ten #1 seeds will probably score 198 total points in aggregate per tournament.
As previously mentioned, that same #1 seed has about a 98% chance of finishing anywhere on the podium. As you work your way down that AA Probability you see that from the #1 seed to the #7 seed have a greater than 50/50 shot of appearing in the parade of All-Americans, but the #8 seed only has a 47% chance.
We will come back to the implications of this below.
Blah, Blah, Blah. Is The Model Any Good?
It has been said that the best model of the world is the world itself. Unfortunately, to model that requires a model bigger than the world itself, so it has little utility.
Practically, the goal is to have the simplest model that has some minimum predictive power. What is that minimum? I have no idea in this context, but in financial markets the minimum is whatever makes money.
I suppose you could test these outputs by placing bets to see if it makes money. While prediction markets have exploded this year for reasons4, I am not sure they are robust enough in wrestling to truly test it, but I also haven’t looked so…maybe?
Absent putting money on the line, the best I can do is use last year’s model and line it up against last year’s results. If you squint, it looks… not bad?
A big miss at the #5 seed (six, 6*%^?, of them lost Thursday night and failed to AA). Small misses at the #2, #3, and #6 seeds. Pretty much nailed #1, #4, #7, #8, #9, #11, and a few others. Things get a bit more random after that, but the magnitudes are pretty small given the small number of points available to non-placers.
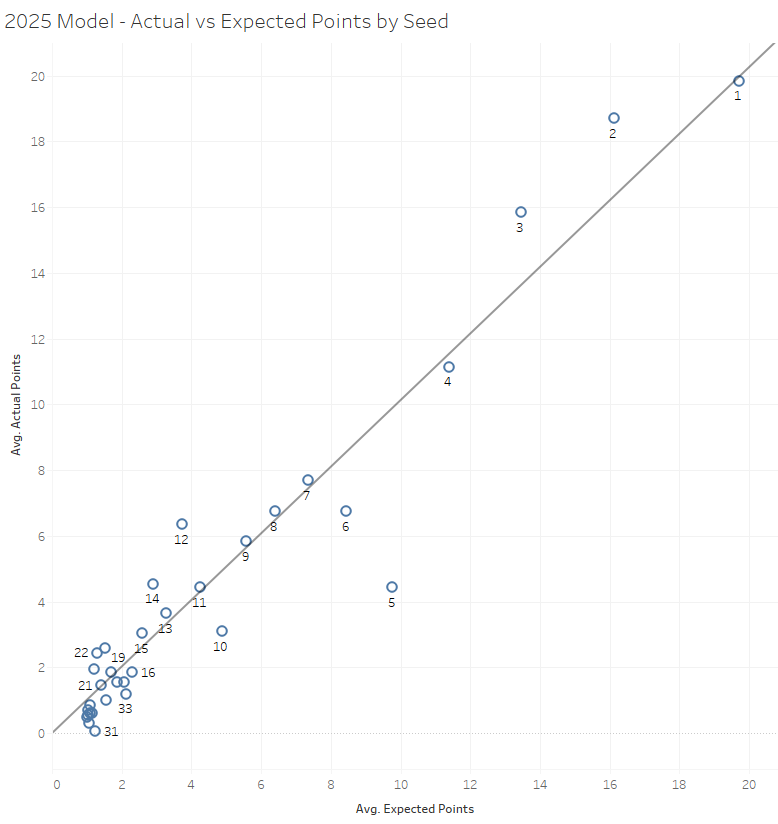
I’m gonna call that good enough for government work. Reasonable minds can differ.
The Other Guys
No one else I know of uses an expected points model when translating their rankings into team score predictions. Instead they assume that the #1 ranked wrestler will finish first, the #2 ranked will finish second, and so on. This means that the #9 ranked wrestler, in their world view, will always fail to earn placement points. But we have already seen that is not true.
So who ya gonna believe? Them or your lying eyes?
In this next graph I am using the Flo team scoring model to compare to expected points. This is not to single Flo out; Wrestlestat and InterMat do the same thing. Flo just makes it easiest to find. Thanks, Flo.
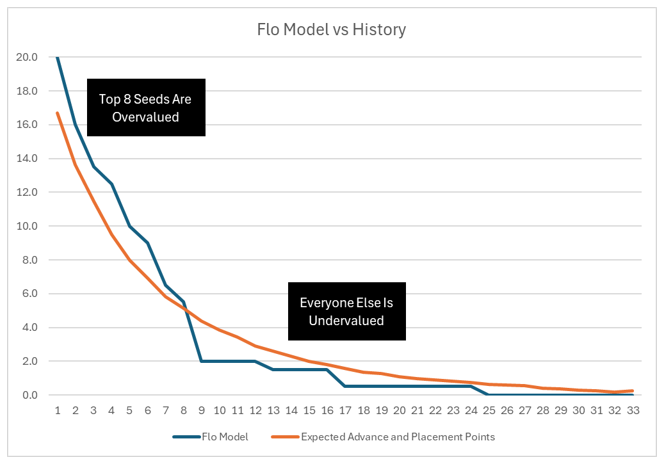
The Flo/Wrestlestat/InterMat model assumes every bracket will go according to chalk. But no bracket of this size ever, in any sport, has gone to chalk. Not even close. The net result of their choice is their method overvalues top 8 seeds and undervalues everyone else.
If a hypothetical team entered the tournament with ten wrestlers who all had #9 seeds, their models would have you assume they would score only 20 advancement points and 0 placement points. Perhaps some bonus too, but that is it. That would typically place a team outside of the top 20.
But that logic defies the history of the tournament. In reality a team of all #9 seeds is pretty strong. They are likely to have 4 or 5 AA’s when all is said and done, and they should score around 44 advancement and placement points plus around 10 bonus points for a total team score of 54 points. That would be good enough for a top 10 finish most years – and as high as fifth in 2025 when Penn State hogged all the points.
Is This Lake Wobegon?
No, it is not. All of our children are not above average.5
While I am using averages I am somewhat ignoring the fact that the average comprises a lot of numbers that are not the average. Yep, there is a distribution to this data.
Is that problematic? Depends.
So far, I have mostly used the data to predict team points. Since the top teams typically have 8-10 wrestlers in the tournament using the average works pretty well. The overperformances and the underperformances within a large team tend to offset (there are notable exceptions – Nebraska last year in the overperform category, NC State in 2024 in the underperform category – that I will explore in a later post).
But the model can break down a little the further down the team rankings you go. At the extreme a “team” with one wrestler entered is kinda hard to account for. I am going to work on that too. Stay tuned.
But the good news is that for the past three tournaments the percentage difference between the expected points and the actual points is highly normally distributed for the top 20 teams, or so.
Knowing that we can use z-scores to create probability distributions around the expected team score. Hooray.
But that is another post.
wrestleknownothing@gmail.com
@wrestleknownothing.bsky.social
- Not yet 100% accurate (and perhaps it never will be), but better than anything that is available anywhere else. ↩︎
- As more data accumulates in the 33 seed era (2019-present) I will phase out data from the 16 seed era. Or at least that is the plan. ↩︎
- Or 4 for places 9 – 12, and 13 – 16, 8 for places 17 – 24, and 9 for places 25 – 33. ↩︎
- I won’t get into it here. Email me if you want to here more about the reasons. ↩︎
- Though I know our women are strong and our men are good-looking. ↩︎
Leave a Reply to Gaylon Sells Cancel reply